This is the third in a multipart series that explores machine learning (ML) within cybersecurity. The first post in this series provided a brief background to set the stage. The second article examined how ML models and data might be attacked. In this third installment, we will explore how we can make ML more secure. Stay tuned for the final installment, which will discuss some ethical considerations regarding ML.
Fortunately, there are several steps we can take to help protect ML data and models. The foundational elements for securing ML include a mixture of fundamental security practices and methods specific to ML. This section looks at various aspects of securing ML when used in an adversarial environment, such as cybersecurity.
Sanity Check Training Data
Much of the effort in developing effective training models goes into data collection and preparation. The learning is based on historical data, which defines the ground truth. The data’s quality, quantity, and relevance will affect the learning. Often, the data must be cleansed, and many of the decisions, such as how to deal with missing data, can greatly impact learning. Should the missing data be ignored, or should it be imputed? If imputed, by what means? Similar considerations must be given to outliers. Also, the data distribution can affect which ML methods to use
Training Data and Model Protection
Security fundamentals such as version control and access control are extremely important, especially related to the training data and models. Protecting the data and models from unauthorized access is paramount to guard against poisoning attacks. Effective version control of the data and models will also allow for reverting to a known good state in the event of an attack or error. Like with traditional software development, solid change management processes are a must.
Robust Learning
Improving the robustness of the learning algorithms to guard against poisoning attacks is a burgeoning area of research. Robust learning seeks to make the model inherently less susceptible to adversarial data or outliers. During the testing phase of a new classifier model, the designer can simulate attacks to see how the model responds. The classifier model can then be updated based on the results of the test attack. The result is a more robust model that is less susceptible to disruption due to poisoning. Another method used to create a more robust classifier is bagging (using multiple classifiers).
Detecting Attacks
The community needs to do more research on how to detect attacks during the training and testing phases. Current research includes analyzing model drift. However, a natural drift is associated with changing attack parameters and methods in many cybersecurity use cases. Distinguishing drift caused by a low and slow attack may prove difficult. This drift is another reason for version control of the training data. The original training data could be run back through the model to see if it produces the same results.
However, with online training, the live production environment is often used for initial training or periodic retraining of the models. This online retraining is typically done to adjust models to subtle changes. Therefore, with online training, detecting malicious subtle drift may prove extremely difficult. An alternative would be to use offline training with periodic snapshots of data. Before retraining, the sanity checking of training data and versioning discussed earlier can be used to help detect adversarial data.
Deploy Clustering with Extreme Caution
Use caution when deploying clustering ML models for cybersecurity use cases, especially for classification systems. Classifiers that leverage clustering algorithms are particularly susceptible to evasion attacks. If an adversary knows the state of clusters, the adversary can easily craft a new data point near one of the clusters. Until further research can improve the robustness of clustering, such methods should be used with great caution in cybersecurity.
Using Adversarial ML to Improve Models
Though ML has had many successful real-world applications, its methods have not been as successful as possible in the cybersecurity field. Classical ML methods and models do not consider purposeful misleading of the ML system by an adversary. Traditionally, ML has focused on uncovering knowledge and discovering relationships within all data supplied. As was shown previously, adversaries seek to exploit ML vulnerabilities to disrupt ML systems. Cybersecurity systems, including ML models used in cybersecurity, must be designed to assume that an adversary will attempt to exploit the system and disrupt the model. In the ML field, the data distribution within the test data is typically assumed to be statistically similar to the training data distribution. However, this assumption may not hold in cybersecurity if an adversary is actively manipulating the testing data.
Unfortunately, many methods used to assess the performance of an ML model evaluate the model under normal operation instead of in an adversarial context. The adversarial ML field seeks to improve ML algorithms’ robustness, security, and resiliency in adversarial settings, such as cybersecurity. The three main pillars of adversarial ML research are (a) recognizing training stage and inference stage vulnerabilities, (b) developing corresponding attacks to exploit these vulnerabilities, and (c) devising countermeasures. With adversarial ML, the security team proactively attempts to exploit vulnerabilities, much like red teaming in traditional cybersecurity.
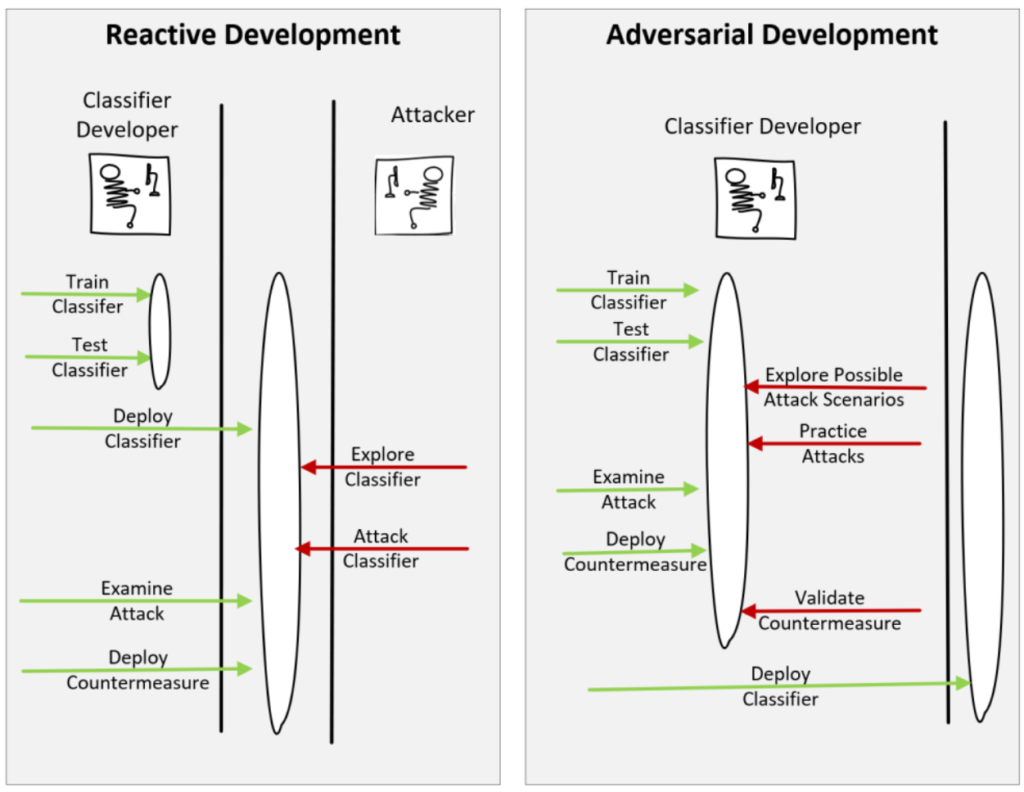
Conclusion and Recommendations
As we have seen, ML offers tremendous benefits when applied to cybersecurity. However, we must understand the limits and vulnerabilities of ML. Cybersecurity is an adversarial environment. We must realize that traditional ML methods do not consider willful misleading or disruption by an adversary. Furthermore, deploying poor ML models is easy, but deploying robust, secure ML models requires much effort. The following recommendations can help ensure the safe and efficient use of ML within an adversarial environment.
- The training data used for ML must be sanitized. Proper data collection and preparation can reduce errors introduced through poor data.
- Strict version and access controls must be employed to protect the training data and the models.
- ML processes and data must be evaluated to understand where they may be vulnerable to attack.
- When applying ML to cybersecurity, we must assume the data and models will be attacked. Therefore, we should employ adversarial development methods when developing models for an adversarial environment, such as cybersecurity.
- Caution must be used when employing clustering methods within an adversarial environment, especially for classification. Clustering methods are particularly susceptible to evasion attacks.
The use of ML within cybersecurity will expand rapidly. We are only beginning to unleash the potential of ML. This is an exciting time, full of promise. However, we must ensure that this promise is realized safely and securely.
Stay tuned for the next paper in this series, which will discuss some ethical considerations regarding ML.
About the author: Dr. Donnie Wendt, DSc., is an information security professional focused on security automation, security research, and machine learning. Also, Donnie is an adjunct professor of cybersecurity at Utica University. Donnie earned a Doctorate in Computer Science from Colorado Technical University and an MS in Cybersecurity from Utica University.