This post is the first in a multi-part series exploring machine learning (ML) within cybersecurity. When I first entered the security field (many years ago), it was accepted that cybersecurity professionals needed to understand the essentials of networking, operating systems, and software development. With the increasing importance that Cybersecurity will play in both offensive and defensive aspects of cybersecurity, I believe we must add ML to that basket of essentials for cybersecurity professionals. This first post is designed to provide a brief background to set the stage. In the near future, I will post the second article in this series, which will look at how ML models and data might be attacked. Finally, the third installment will investigate how to make ML models more secure.
Machine learning (ML) is widely used within cybersecurity, as evidenced by all the products touting ML and artificial intelligence (AI). The power of ML to analyze large amounts of data efficiently, accurately, and quickly ensures that the use of ML in cybersecurity will continue to expand rapidly. Of course, based on much of the marketing material for these security products, ML and AI appear to be magical fairy dust. Just sprinkle a little here and a little there; the next thing you know, the product has learned your environment. This paper will help demystify ML so that security professionals can harness the great potential of ML within the cybersecurity domain.
The purpose of this paper is to provide cybersecurity professionals with a brief introduction to fundamental ML concepts. As a plethora of cybersecurity products claim ML benefits, it is imperative that cybersecurity professionals understand what ML is and how it works. The cybersecurity professional’s need for this knowledge is multifaceted. Understanding ML concepts is foundational to determining the efficacy of and protecting the ML models used by cybersecurity products and services.
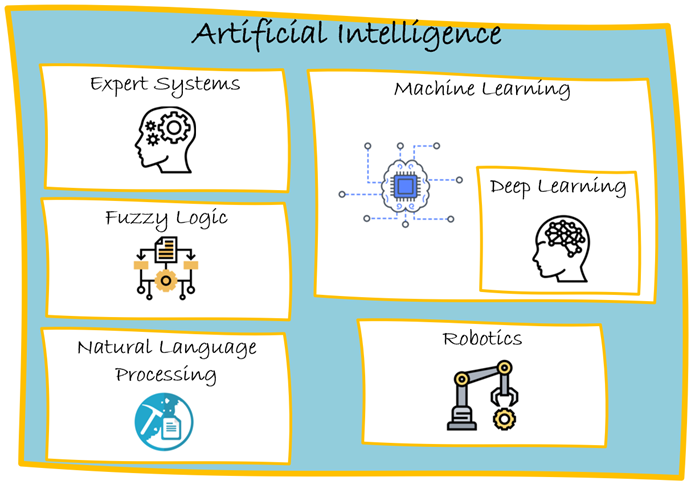
Machine Learning Overview
The terms AI and ML are often used interchangeably, causing confusion. ML is a subset of AI, which includes several other fields of study. Many analogies compare ML to human thinking; however, ML does not operate like human brains. Instead, ML is based on statistics and applies algorithms to teach machines how to discover or acquire knowledge and make decisions. One aspect in which human learning and machine learning are similar is in that they seek to generalize.
Machine learning and deep learning trace their roots back to the 1950s. Intense academic research focused on ML, especially on neural networks, during the 1970s and 1980s, when many of the algorithms that are in use today were first developed. However, insufficient processing power and data led to a period known as the Neural Winter, which lasted from the late 1990s until about 2007. New technology, including graphics processing units (GPUs) for training, and the advent of big data, powered a resurgence of ML research and practical application.
ML methods can empower systems to improve without explicit programming [5]. These techniques are broadly classified as supervised, semi-supervised, unsupervised, or reinforcement learning. Machine learning models can recognize patterns in data (pattern recognition), classify input (generalization), forecast based on known data (regression), and detect outliers (anomaly detection).
Supervised Learning
Supervised learning, also known as predictive learning, has a target variable and the ML model learns to predict or classify the value of the target variable based on features. Supervised learning requires that the data be labeled, such as transactions marked as fraudulent or not fraudulent. After learning, these labels can be applied to new observations. Popular classification algorithms include decision trees, support vector machines (SVM), naïve Bayes, and k-nearest neighbors (kNN). Predictive algorithms include linear and logistic regression.
Decision trees are tree-structured, rule-based classification models. The features are organized as nodes on the tree to optimally split all data into the classes (represented by the leaves on the tree). A decision tree algorithm is easy to implement, provides accurate classification, and is easily explained. However, a significant disadvantage of a decision tree is its computational complexity. Decision trees are often used as a collaborative classifier with other ML algorithms for intrusion detection.
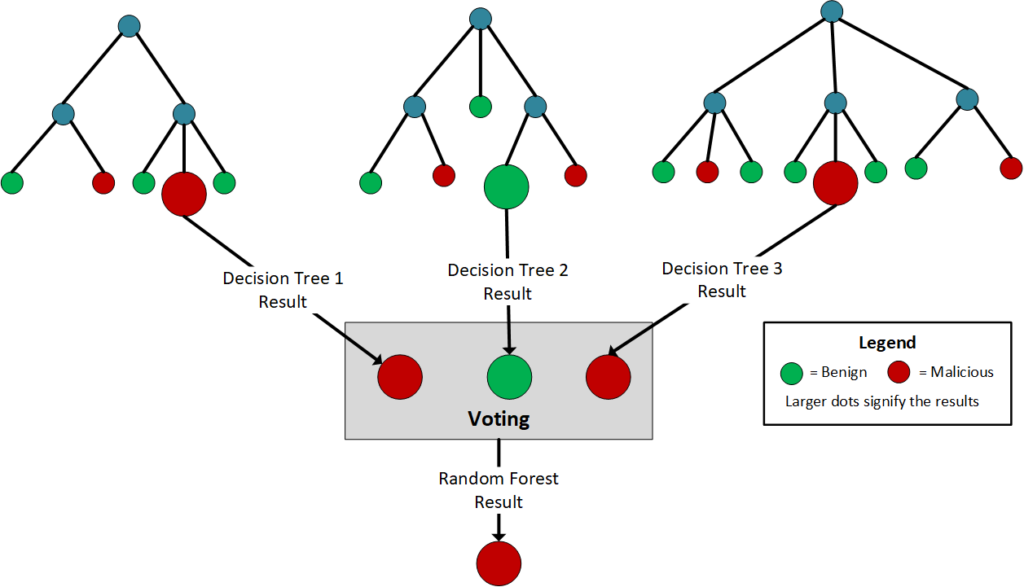
Random forest is an example of an ensemble training method, meaning it employs multiple algorithms. A random forest typically consists of multiple decision tree classifiers that are run in parallel. Once all the decision trees are finished, the result is determined either by majority vote or averaging.
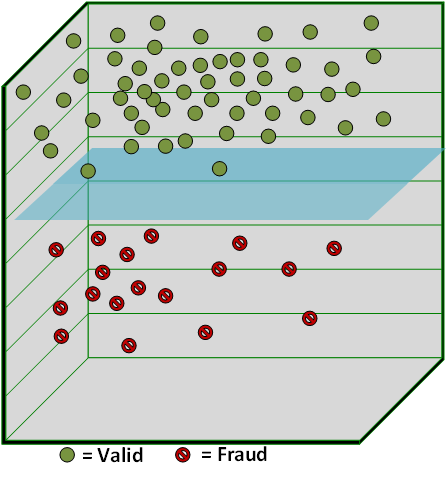
An SVM is a classification model that finds a separating plane between classes within the feature space. The plane defines the decision boundary between the classes. The plane is chosen to maximize the distance between the decision boundary and the data points. SVMs are among the most popular algorithms used within cybersecurity because of their ease of implementation and accuracy when there are many features. A significant downside of SVMs is that they often result in a complex black-box model, making them difficult to interpret or explain.
A Naïve Bayes classifier determines the probability that an input belongs to a class based on the features. The posterior probability is determined based on the conditional probability of all features given a class and the prior probability of all classes. A naïve Bayes classifier is robust when presented with noisy training data. Also, this classifier performs well with a low number of training samples. However, the naïve Bayes algorithm considers all features as independent contributors to the posterior probability, which is rarely the case.
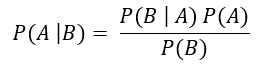
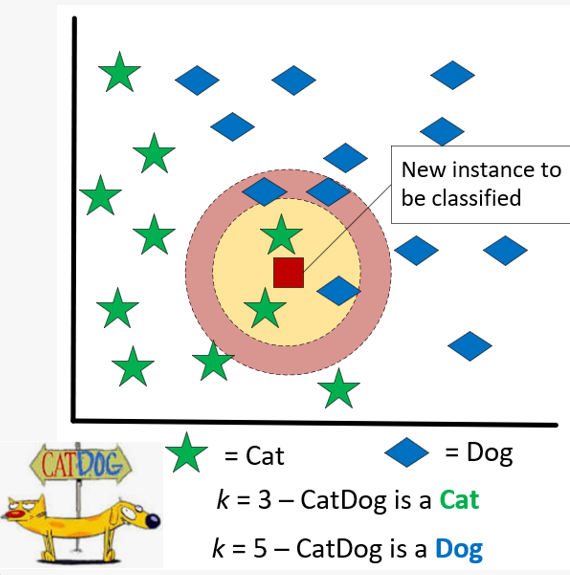
The kNN algorithm is one of the simplest forms of ML and is widely used for classification. Nearest neighbor algorithms classify unlabeled examples by assigning them the class of similar labeled examples. The algorithm will find the nearest k training samples, based on Euclidean distance, to the unlabeled record. The unlabeled instance is assigned the majority class of the k-nearest neighbors. The kNN algorithm is considered lazy because no abstraction or generalization occurs, producing no model. Therefore, the kNN algorithm is technically not a form of machine learning because it does not learn anything.
With k-NN, selecting a different number of comparison samples can lead to a different result. If you use the 3 nearest samples, CatDog is a cat, but if we expand out to 5 samples, CatDog is a dog.
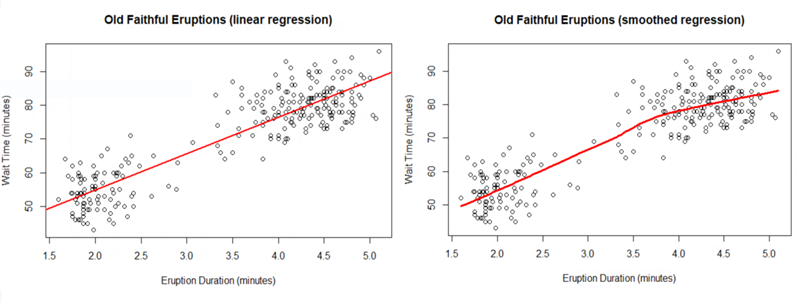
Linear Regression is used to predict a numeric result (known as the dependent variable) by defining the relationship between the dependent variable and one or more numeric predictors (independent variables). Regression methods model the size and strength of the relationships between numeric variables. The simplest form is linear regression, which assumes the relationship follows a straight line. The regression line, defined by the slope and intercept, maps this relationship. One method to determine the regression line is ordinary least squares (OLS) estimation. With OLS, the regression line is chosen to minimize the sum of the squared errors. The error (also known as the residual) is the distance between the predicted value and the actual value.
Of course, most relationships are not strictly linear. Smoothing attempts to adjust the regression line to better fit the data, often using local polynomial regression. Common methods include LOESS (locally estimated scatterplot smoothing) and LOWESS (locally weighted scatterplot smoothing).
Whereas linear regression is used to predict a numeric result for a continuous value target variable, logistic regression can be used to predict categorical outcomes, like the classification methods discussed previously. Simple logistic regression predicts a binary categorical outcome. In contrast, multinomial logistic regression can be used for classifications involving multiple outcome classes.
Unsupervised Learning
Unsupervised learning models evaluate the training samples with no prior knowledge of the corresponding category labels. Often, unsupervised learning aims to cluster or group samples based on their similarities. The unsupervised ML models discover interesting patterns or associations within the data. Common unsupervised ML algorithms include k-means clustering (kMC) and market basket analysis (MBA).
k-Means clustering (kMC) is used to discover clusters within the data set, where k defines the number of clusters. The algorithm creates the clusters based on the similarity of all data points. Euclidean distances are used to determine which cluster to assign each item. Advantages of kMC include using simple, explainable principles and its performance under many real-world use cases. However, since kMC does incorporate random chance, it may not find the optimal clusters.

Market basket analysis (MBA), also known as affinity analysis, originated in the marketing industry to discover relationships between groups of products. Merchants sought to use MBA to identify shopping patterns to improve product placement, increase cross-selling, and support advertising. The ability of MBA to discover nonobvious relations or association rules between items makes MBA a powerful tool beyond its original purposes in marketing. MBA develops association rules to specify the relationship patterns between item sets.
An association is determined by the lift, which is the probability of A and B occurring together divided by the probability of A times the probability of B. Lift scores greater than 1.0 describe a positive relationship. In contrast, lift scores below 1.0 describe a negative relationship. A lift value of 1.0 indicates that chance can explain the relationship. The support defines the probability that the items co-occur within the data set. The confidence of a rule is the measure of its predictive accuracy and is the probability that B will be selected given A’s selection.
Deep Learning and Artificial Neural Networks
Deep learning (DL), a subset of ML, attempts to imitate the human brain to analyze and interpret the data. Artificial neural networks (ANN), which underly DL, are inspired by the working of neurons in the brain. An artificial neuron can be understood in terms similar to a biological model. The input signals are weighted according to their importance. These weights are summed, and the signal is passed on based on the activation function.
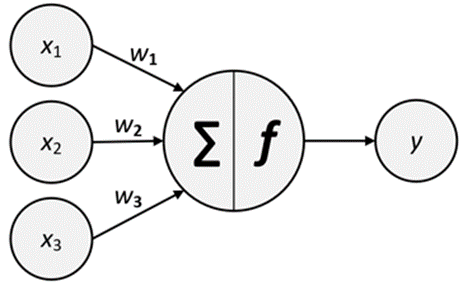
An ANN is composed of nodes and has three layers: the input layer, hidden layer, and output layer. A deep neural network (DNN) is an ANN with multiple hidden layers. Traditional ANNs were popular in the early days of machine learning. With the advent of DNNs, including recurrent, feed-forward, adversarial, and convolutional neural networks, the use of ANNs has seen a resurgence and gained popularity in the cybersecurity field.
Whereas other ML methods degrade with very large data sets, deep learning (DL) thrives. The concept behind DL is that the performance will increase by constructing larger DNNs and training them with as much data as possible. The DNNs use hierarchical-based feature abstraction and representation to handle extremely large training data sets with ease.
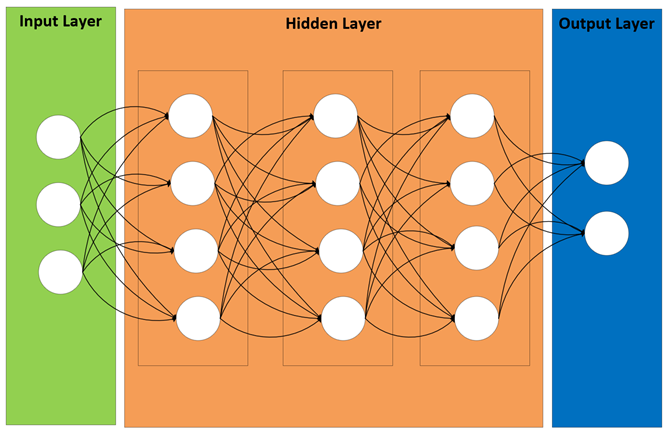
There are many variations of DNNs, including recurrent neural networks (RNN) and convolutional neural networks (CNN). An RNN includes feedback links making them well-suited for use with sequential data. CNNs are widely used in image processing and classification. In addition to the hidden layers within an ANN, an RNN includes convolution layers, which put the images through convolution filters to activate features within the images.
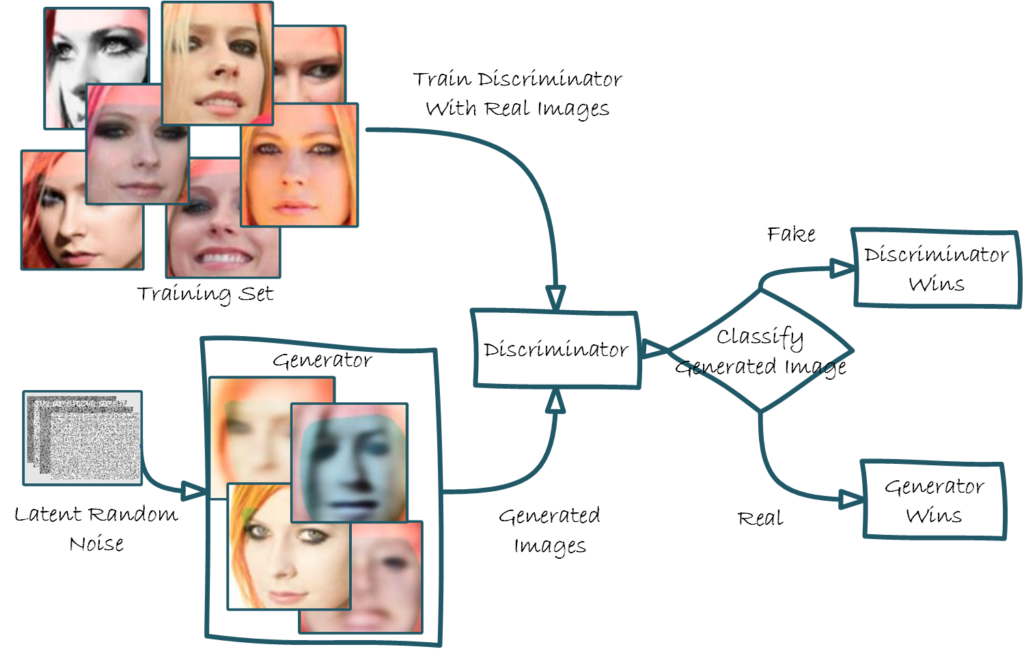
A generative adversarial network (GAN) pits two DNNs in a battle against each other using discriminative and generative algorithms. The discriminator is a typical machine learning classifier. The generative algorithm generates samples from the latent space. The goal is for the generative algorithm to create a sample that appears authentic. The discriminator model is updated with each iteration, so it gets better at discriminating. Meanwhile, the generator is updated based on its performance against the discriminator. The competition continues until the discriminator is fooled about 50% of the time, indicating that the generator makes plausible samples.
Application of ML to Cybersecurity
Employing machine learning for cybersecurity offers tremendous benefits and has become a vital component in many security solutions. Cybersecurity products implement ML for many use cases, including spam filtering, intrusion detection, botnet detection, phishing detection, malware detection, biometric recognition, and anomaly detection. The following sections highlight a few of the uses of ML in cybersecurity.
Malware and phishing detection. Malicious and benign executables are collected and then split into training and testing data sets. The discriminative features are extracted and selected. The classifier is then applied to the training data set, and the parameters are tuned. The resulting model is then applied to the test data set to determine accuracy. The malware and phishing detection classifiers typically rely on naïve Bayes, SVM, decision tree, or DL algorithms.
Intrusion detection. A typical approach to applying ML and DL to intrusion detection begins with collecting network data. The features are selected either through feature engineering or extraction. These features are used to build the intrusion detection system (IDS). The IDS’s analysis engine is applied to discover existing attacks based on the features. The ML and DL algorithms used for intrusion detection include random forest, SVM, and RNN. In addition to ML and DL, other AI techniques, including fuzzy logic and expert systems, have been used for intrusion detection.
User behavior analytics (UBA) seek to detect threats by defining normal behavior and then detecting deviations from normal behavior. Data mining and ML can identify normal behavior for users, such as what data the user accesses, what programs the user runs, at what time the user accesses the system, how long the user remains on the system, and what systems the user accesses. Then, ML algorithms are used to discover outliers, which may be time-based (user behavior changes over time) or peer-based (user behavior is different from a peer group). These same methods can be applied to computer systems to detect possible attacks.
Network risk scoring helps organizations prioritize cybersecurity resources by assigning relative risk scores to various components based on quantitative measures. ML can help automate the process and ensure data-driven risk scoring. Several ML methods, including kNN and SVMs, have been used to analyze and cluster assets to define risk scores based on the likelihood and impact of an attack.
Vulnerability exploit prediction. The Common Vulnerability Scoring System (CVSS) is not an effective predictor of a vulnerability being exploited. Many recent studies focus on predicting when a vulnerability will be exploited. The goal is to assist software vendors in prioritizing patch development since less than 3% of vulnerabilities on the National Vulnerability Database (NVD) are exploited [1]. Researchers use ML models that leverage multiple data sources to aid in predicting if and when an exploit of a vulnerability will be seen in the wild. Such data sources include ExploitDB, Zero Day Initiative, threat intelligence feeds, scraping of dark websites, and social media, such as Twitter [1] [2] [3] [4]. These approaches use several ML methods, including ANNs, logistic regression, SVM, natural language processing, and naïve Bayes, often combining multiple methods.
Conclusion
Machine learning is a broad field of study that includes many existing and emerging methods. The roots of machine learning, including some of the algorithms in use today, can be traced back many years. Recent advances in technology, especially big data and the increased processing power of GPUs have begun to unleash the power of ML.
There are many approaches to ML, and no one model or process will fit all applications. The question to be answered and the available data will determine the optimal ML strategy. Supervised learning often employs popular classification algorithms, such as decision trees, SVM, kNN, and naïve Bayes. Supervised learning can also be used for prediction using linear and logistic regression. Unsupervised learning, including MBA and kMC, is used to discover patterns and relationships within data.
Within cybersecurity, ML offers great promise. Cybersecurity products implement ML for many use cases, including intrusion and malware detection, spam filtering, phishing detection, biometric recognition, and anomaly detection. The power of ML to analyze large amounts of data efficiently, accurately, and quickly ensures that the use of ML within cybersecurity will continue to expand rapidly. Stay tuned for the next paper in this series, which will examine the possible vulnerabilities of using ML in an adversarial environment like cybersecurity.
About the author: Dr. Donnie Wendt, DSc., is an information security professional focused on security automation, security research, and machine learning. Also, Donnie is an adjunct professor of cybersecurity at Utica University. Donnie earned a Doctorate in Computer Science from Colorado Technical University and an MS in Cybersecurity from Utica College.
References
[1] M. Almukaynizi, E. Nunes, J. Shakarian and P. Shakarian, “Patch before exploited: An approach to identify targeted software vulnerabilities,” in Intelligent Systems Reference Library, 2019.
[2] K. Alperin, A. Wollaber, D. Ross, P. Trepagnier, and L. Leonard, “Risk prioritization by leveraging latent vulnerability features in a contested environment,” in ACM Workshop on Artificial Intelligence and Security, London, UK, 2019.
[3] H. Chen, J. Liu, R. Liu, N. Park, and V. S. Subrahmanian, “VEST: A system for vulnerability exploit scoring & timing,” in International Joint Conference on Artificial Intelligence, 2019.
[4] Y. Fang, Y. Liu, C. Huang, and L. Liu, “FastEmbed: Predicting vulnerability exploitation possibility based on ensemble machine learning algorithm,” Plos One, 2020.
1 thought on “Machine Learning Overview for Cybersecurity Professionals”
Comments are closed.