This is the second in a multi-part series that explores machine learning (ML) within cybersecurity. The first post in this series provided a brief background to set the stage. In this second article, I examine how ML models and data might be attacked. Stay tuned for the third part, in which I will discuss how to make ML more secure.
Machine learning (ML) for cybersecurity offers tremendous benefits and has become a vital component in many security solutions. However, there are also many risks that security professionals must understand when deploying ML as a component of a cybersecurity solution. This article examines possible vulnerabilities and risks, including attacks on the ML process, data, and models.
The Machine Learning Process
First, we will review the ML process. Of course, there is no single approach to performing ML; the nature of the data and the algorithm will dictate the ML technique. However, a generic model can be used to explain the process, as shown in Figure 1.
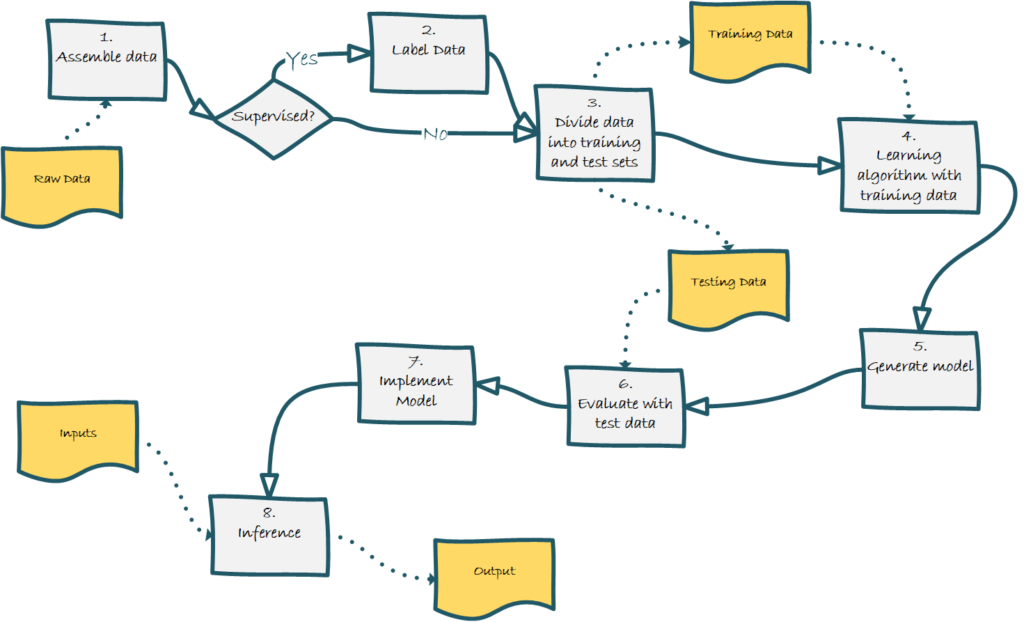
- In data assembly, the data is collected, and we must ensure all the elements necessary to train the model are included. This initial step often includes data transformation and sanitization to prepare it for use.
- If we are using supervised learning, we must label the data.
- Next, the data must be divided into training and testing sets. The testing set is set aside to be used for testing the developed model after training. No set rules exist for how much data we should reserve for testing versus training. However, a typical classification model development might set aside 25% of the data for testing. A cardinal rule of ML is not to use any testing data during training. The testing data is used to see how well the resulting model.
- Once the data is ready, we can start training the model. Often, this step is iterative as parameters are changed to improve the model.
- The training generates a model that can be applied to other data.
- After generating the model, we must evaluate the model using the testing data. The model is applied to the test data to determine the out-of-sample error rate. If the results are unsatisfactory, we could a) discard the model, b) adjust the algorithm and retrain, or c) retrain with a different algorithm.
- Implement the Model – If the testing results are satisfactory, the model is then implemented.
- When the model has been implemented, this is considered the inference stage. The model is now processing previously unseen data and performing its objective, such as classifying, categorizing, predicting, or detecting anomalies.
The Happy Path
Classical ML does not consider purposeful misleading by an adversary. Traditionally, ML focuses on uncovering knowledge and discovering relationships within the data and assumes a non-adversarial environment. For most traditional ML problems, such an approach is acceptable and efficient. (Refer to the previous paper, Machine Learning Overview for Cybersecurity Professionals, for background on ML and its uses within cybersecurity).
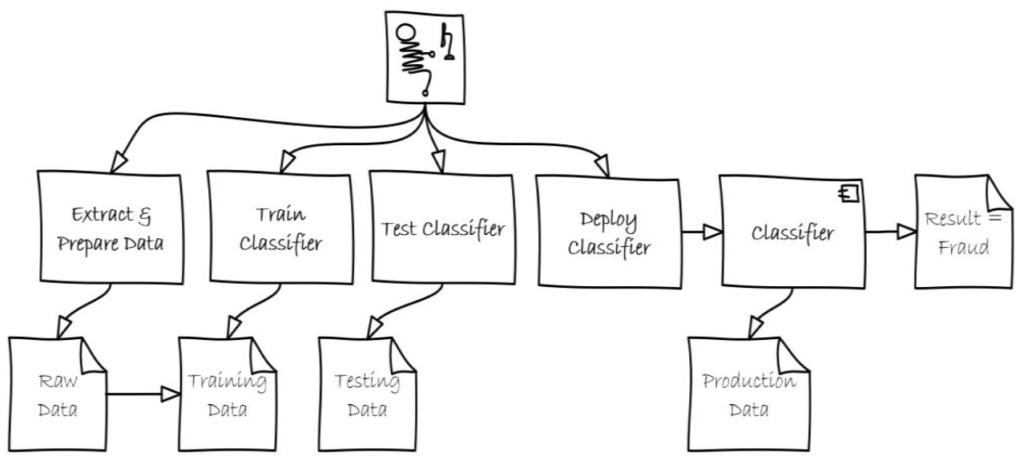
The Not-So-Happy Path
However, this process raises some serious concerns when it is applied to cybersecurity. Unlike many other applications of ML, cybersecurity is an adversarial environment. Adversaries seek to exploit ML vulnerabilities to disrupt cybersecurity ML systems. When ML is used in an adversarial environment, it must be designed and built, assuming that it will be attacked in all phases. Figure 3 depicts the same ML process within the context of an adversarial environment. The following section will discuss the various types of attacks shown in Figure 3.
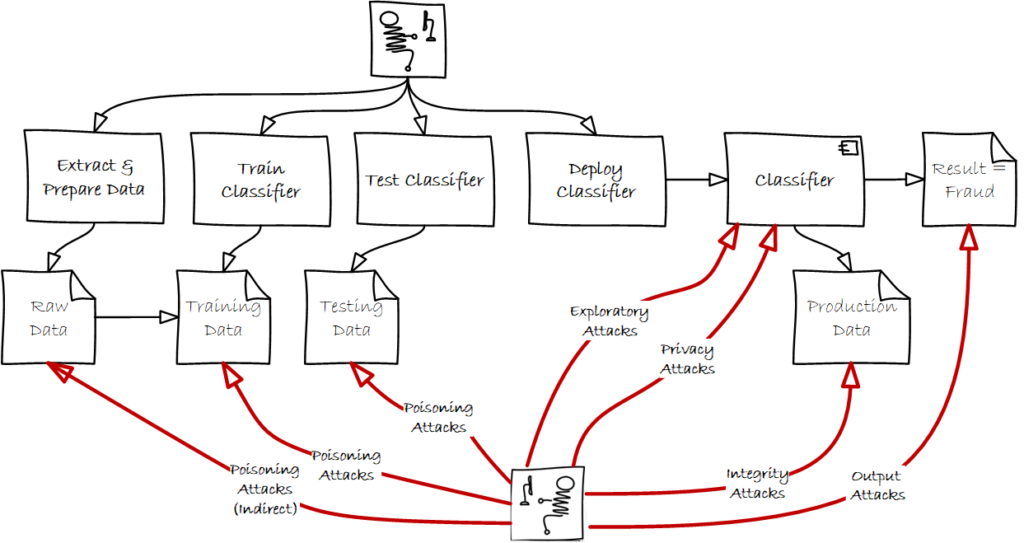
Attacks on Machine Learning
Though ML has had many successful real-world applications, including in cybersecurity, its methods are vulnerable. Attacks on ML can be categorized based on the phase (training, testing, or inference). These ML attacks can also be classified as causative or exploratory. Causative attacks, which typically occur in the training stage, alter the training data or model parameters. An example of a causative attack is injecting adversarial samples into the training data. In contrast, an exploratory attack does not tamper with the training data or the model. Instead, during the inference stage, an exploratory attack collects information about the data and the model, possibly to evade classification later.
Training and Testing Phase Attacks
Poisoning attacks are causative attacks that alter the training data or model parameters. Since ML methods rely on the quality of the training data, they are vulnerable to training data manipulation. In poisoning attacks, attackers inject adversarial samples into the training data set or manipulate labels to impact the ML algorithm’s performance. The poisoning can also be either direct or indirect. Direct poisoning targets the training data set. Indirect poisoning injects data into the raw data before preprocessing and extracting the training data set.
Since the training data set is often well guarded, poisoning attacks against the original training data set may be difficult. However, in a changing environment, ML models may require retraining so they can adapt. Attackers seek to exploit the need for retraining by targeting the retraining stage of an ML model. For example, an ML model that seeks to determine anomalous network activity must periodically be retrained. An adversary could launch a poisoning attack during this retraining phase by injecting adversarial data.
Inference Phase Attacks
Exploratory attacks do not tamper with the training data or the model. Instead, an exploratory attack collects information about the training data and the model during inference, often as a precursor to an integrity attack. The attacker could use reversing techniques to discover how the ML algorithms work or to reconstruct the model.
Privacy attacks are exploratory attacks that target the data. Attackers launch privacy attacks to extract or reconstruct training data, infer class membership information, or infer properties about the training data, such as class distribution.
Integrity attacks, often called evasion attacks, seek to evade detection by producing a false negative from a classifier. The adversary aims to produce a negative or benign result on an adversarial sample, thereby evading classification by the cybersecurity system. Such attacks often rely on exploratory attacks to understand how the classifier works. Another type of integrity attack is analogous to a denial of service. Such an attack causes the classifier to misclassify many benign samples, increasing false positives for the security team to evaluate.
Output integrity attacks — analogous to man-in-the-middle (MiTM) attacks — do not attack the ML model directly. Instead, these attacks intercept the result from an ML classifier and change it. For example, with a malware classifier, the attacker could intercept the result and change that result from malicious to benign.
Conclusion
As we have seen, the traditional ML process does not consider an adversary actively targeting the process. However, all phases of the machine learning process are subject to attacks. We must understand the vulnerabilities in the ML process and the attacks that target them.
Stay tuned for the next paper in this series, which will explore how we can make ML more secure in an adversarial environment like cybersecurity.
About the author: Dr. Donnie Wendt, DSc., is an information security professional focused on security automation, security research, and machine learning. Also, Donnie is an adjunct professor of cybersecurity at Utica University. Donnie earned a Doctorate in Computer Science from Colorado Technical University and an MS in Cybersecurity from Utica University.