Imagine deepfake footage of a major, high-profile company CEO engaging in bribery, U.S. military personnel committing atrocities on foreign soil, or a politician committing a sexual assault just a few days before an election. In our current environment, where conspiracy theories thrive and uncertainty is prevalent, deepfakes could lead to catastrophic consequences. Soon, deepfakes will become a destructive force, both socially and politically. A deepfake video could be the spark to ignite the tinderbox.
What is a Deepfake?
Deepfake refers to tampering or manipulating videos, audio, and pictures to swap one person’s likeness with another. Currently, many of the deepfakes are of celebrities. For example, the internet is home to many funny deepfake videos of Sylvester Stallone. Also, people use deepfake technology to place themselves into famous Hollywood scenes. On a more serious note, many celebrities have been victims of deepfakes that put their likeness into a pornographic video or picture. With the recent advances and expected improvements in deepfakes, the uses are expanding.
In 2017, a Reddit user named deepfake coined the term and created a space to share pornographic videos using open-source face-swapping software. Though the term “deepfake” was not coined until 2017, the underlying technology and methods existed prior to that. The computing power, especially of graphics processing units (GPU), and the availability of open-source tools have resulted in a rapid expansion of deepfakes.
Business Uses of Deepfake Technology
Most discussions about deepfakes center on the negative uses, such as exploitation, fraud, and revenge. However, there are legitimate business uses for deepfake technology [1]. Such technology can allow consumers to try on clothes, cosmetics, hairstyles, and eyeglasses virtually. Audio deepfakes can be used to create audiobooks with realistic characters. Movie studios can use the technology to put an actor’s face on a stunt double’s body. Video games could allow players to put their faces on characters within the game. Deepfake technology is not limited to people. The technology can be used to see what your home would look like with various flooring. Gone are the days of trying to pick out flooring from a one-square-foot sample. When used for positive purposes, many people prefer the term AI-generated synthetic media over deepfake.
Generative Adversarial Networks – The Battle Royal
One of the most common ways to develop models for deepfake videos is by using generative adversarial networks (GANs) [2, 3, 4]. GANs use both discriminative and generative algorithms, pitting them against each other [4]. Discriminative algorithms classify by predicting a category to which an input image belongs based on its features. Generative algorithms generate data so that it appears it came from the dataset. In other words, discriminative algorithms predict a label given the features, whereas a generative model predicts the features given a label.
A GAN is a two-player, zero-sum game that pits two machine learning models against each other [4]. In a GAN, the generative model uses unsupervised learning to discover and learn the patterns in the input data to generate new plausible examples. The discriminator, originally trained using authentic images, tries to classify the examples as real or fake. With each iteration, the discriminator model is updated, so it gets better at discriminating. Meanwhile, the generator is updated based on how well it performed against the discriminator. The key is that both the generator and discriminator are being trained together. The competition between the generator and the discriminator continues until the discriminator is fooled about 50% of the time, indicating that the generator is making plausible examples.
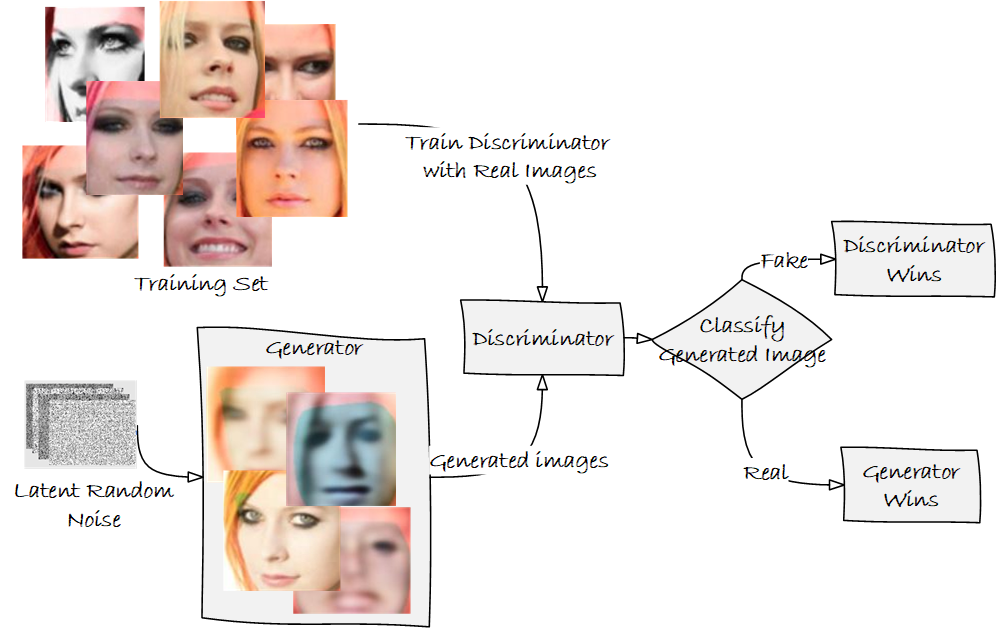
Figure 1 – Depiction of a GAN and the use of a generator and discriminator models
Swapping the Images
One method of swapping the images in videos relies on unsupervised machine learning with two sets of training data: images of the original person (Person A) and images of the replacement person (Person B) [5, 1]. The key is that the same image encoder is used for both training sets to ensure the same features are selected, thus aligning the expressions [1]. The image encoder compresses thousands of pixels into measurements related to facial characteristics. The encoder will typically generate about 300 measurements of distinguishing characteristics, often referred to as the latent space. The encoder allows the deep neural network (DNN) to learn general characteristics instead of memorizing all input images. The shared encoder will learn the general features that the two subjects have in common.
Once the shared encoder has processed both sets of images, images of Person A could be processed by the decoder of Person B. The decoder decompresses the latent space to reconstruct the image. In this case, the decoder draws the features of Person A onto Person B [5]. To relate this to a GAN, the generated fake images are then processed by the classifier of Person B to determine if the result is plausible. The manipulated facial image can then be placed back into the original scene [1].
An example of this process is shown below. In the training phase, the features of Avril Lavigne’s and the author’s faces are extracted using a shared encoder. Typically, thousands of pictures of each would be used in this phase. However, for this example, approximately 400 photos of each subject were used. In the generation phase, the features from an Avril Lavigne picture are extracted and then ran through the decoder for the author. Thus, the author’s face can be placed back into the original scene, complete with Avril Lavigne’s facial expression.
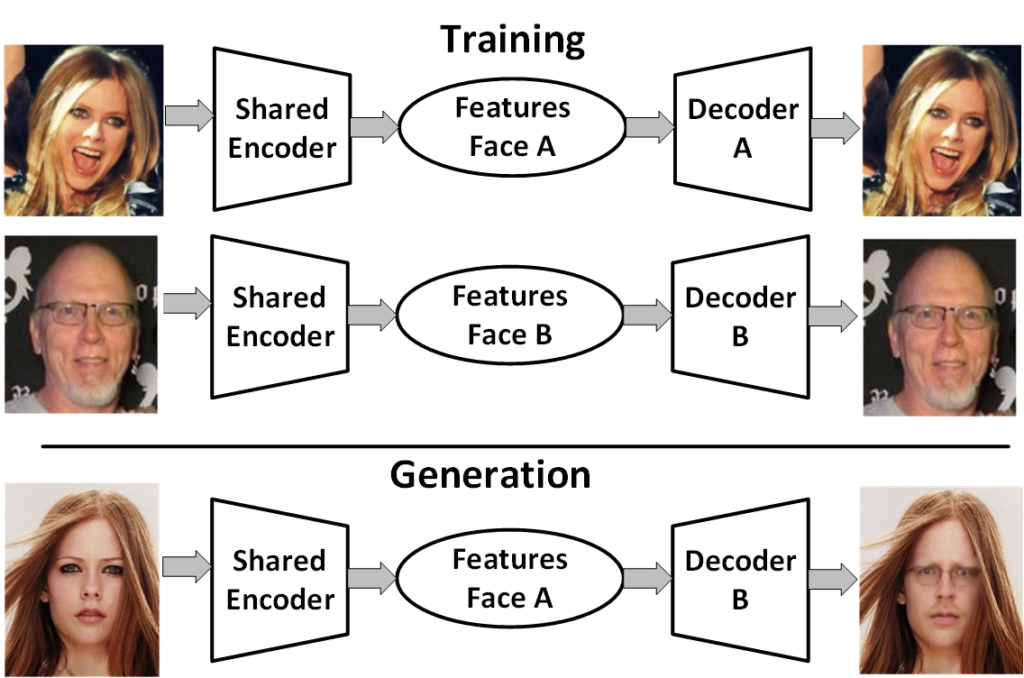
Figure 2 – Generating a fake image using a shared encoder

Figure 3 – The first image is the original with Avril Lavigne. The second one shows the author instead of Lavigne.
Heavy Resource Requirements
The neural networks need many images of each subject, typically at least 1,000. The training also requires a lot of processing resources. Depending on the algorithms, the training may take anywhere from 500,000 iterations to several million. Doing such work on the CPU is not practical. Instead, the processing is typically done on a GPU. Below is an example of the difference in processing time for the dfaker algorithm using the CPU versus the GPU. The computer was a 4-core i7 processor with 32GB RAM. The GPU was an NVIDIA 1060 with 3GB of memory.
| CPU | GPU | |
| Time per iteration | 6.7 seconds | 0.32 seconds |
| Extrapolated time for 1 million iterations | 1,861 hours (77.5 days) | 89 hours (3.7 days) |
Impacts
Facial Recognition
Researchers demonstrated that state-of-the-art facial recognition systems are vulnerable to high-quality deepfakes [6]. The recognition systems, based on VGG and Facenet neural networks, had false acceptance rates between 85% and 95%. As deepfake technology advances, facial recognition technology struggles to keep pace. Any use of facial recognition for authentication must be thoroughly and continually tested against the latest in deepfake technology.
Fraud and Impersonation
As deepfake technology advances, the use of deepfakes to commit fraud and impersonate others will become much more common. To create realistic deepfakes requires many images or videos of the target person. Therefore, high-profile people, including business executives and people who like to post many pictures on social media, could become targets of deepfake impersonations. Consider someone making a video with a fake announcement concerning a company that could negatively impact the company’s reputation. Now, the attackers use deepfake technology to place the face and voice of the CEO on the video, which quickly goes viral.
On a more personal note, what if you post thousands of pictures on social media. Someone who wants to defame you could make compromising videos or pictures with your face. The internet is littered with such deepfakes of celebrities. As deepfake technology becomes more commonplace, many people will soon be able to create these fakes.
Machine Learning Classifiers
Perhaps most importantly, the same concepts and technology that power GANs can target many types of machine learning classifiers. Instead of generating fake images, a GAN could generate any fake data from the latent space. Therefore, adversarial testing of machine learning classifiers is a must.
Detection Methods
The quality of deepfakes is quickly surpassing the ability of humans to distinguish them. Many automated detection methods and proposed methods are based on convolutional neural networks (CNNs) [2, 7]. These CNNs use three general approaches: image-based, fingerprint-based, and spectrum-based [2]. Each of these methods can be used to detect evidence of manipulation by GANs. CNNs can be used to detect temporal artifacts and inconsistencies within a deepfake video [8].
The creation of deepfakes is subject to the biases of the unsupervised learning algorithms [5]. Therefore, eye blinking analysis can detect deepfakes [5, 3]. Without a proportionate number of pictures in which the subject is blinking, the generative algorithm will create faces that do not blink appropriately [5, 8]. Therefore, many deepfakes could be detected by computing the rate of blinking. [3]. In one study, researchers used algorithms that analyzed the patterns of eye blinking, along with cognitive and behavioral indicators of eye blinking, to detect deepfakes and accurately detected 87.5% of the fake videos [3].
Other methods to detect deepfakes focus on the details lost during image compression or encoding [5]. The analysis of the details of eyes and teeth is one such method. The machine learning algorithm attempts to detect missing details, such as the lines between teeth and reflections in the eyes, to identify deepfakes.
Researchers have also used heartbeat rhythms to detect deepfakes [9]. The technique detects the heartbeat rhythm in a video based on the periodic minor skin color changes due to blood pumping through the face. The premise is that the normal heartbeat rhythm would be disrupted in a deepfake video.
The above methods all rely on machine learning to combat machine learning. However, image forensics, which looks at parameters such as lighting, pixel correlation, and image continuity, is, perhaps, the most effective means to determine whether an image has been altered [5]. Of course, as deepfake technology advances, detection methods must also be reevaluated and improved. We now live in a world where perhaps we cannot trust what our ears and eyes tell us.
What Can We Do?
As deepfake videos become commonplace, it may become difficult to trust what our eyes and ears tell us. However, there are things that security professionals and the public at large can do.
- Have fun! By all means, enjoy the harmless videos. Laugh at the Sylvester Stallone deepfakes. Even better, if you are inclined to do so, experiment with the technology. Make your own videos and images. If you have two dogs, how about swapping their faces? Everyone wants to see what your rottweiler would look like with your chihuahua’s face. As a security professional, I find that understanding the underlying technology better prepares me to guard against malicious uses.
- Be cautious about what you post and where. Go ahead and use social media, but be aware of what you share and with whom.
- For those using facial recognition in your systems, ensure to thoroughly and continually test against the latest deepfake technology and algorithms.
- For those using machine learning classifiers, adversarial testing is a must! Include adversarial testing in your machine learning pipeline.
About the author: Dr. Donnie Wendt, DSc., is an information security professional focused on security automation, security research, and machine learning. Also, Donnie is an adjunct professor of cybersecurity at Utica College. Donnie earned a Doctorate in Computer Science from Colorado Technical University and an MS in Cybersecurity from Utica College.
References
[1] J. Kietzmann, L. W. Lee, I. P. McCarthy, and T. C. Kietxman, “Deepfakes: Trick or treat?,” Business Horizons, vol. 63, no. 2, pp. 135-146, 2020.
[2] Y. Huang, F. Jufei-Xu, R. Wang, Q. Guo, L. Ma, X. Xie, J. Li, W. Miao, Y. Liu, and G. Pu, “FakePolisher: Making deepfakes more detection-evasive by shallow reconstruction,” in Proceedings of the 28th ACM International Conference on Multimedia, 2020.
[3] T. Jung, S. Kim, and K. Kim, “DeepVision: Deepfakes detection using human eye blinking pattern.,” IEEE Access, vol. 8, pp. 83144-83154, 2020.
[4] R. Spivak, “Deepfakes: The newest way to commit one of the oldest crimes,” Georgetown Law Technology Review, vol. 3, no. 2, pp. 339-400, 2019.
[5] M. Albahar and J. Almaki, “DeepFakes: Threats and countermeasures systematic review,” Journal of Theoretical and Applied Information Technology, vol. 97, no. 22, pp. 3242-3250, 2019.
[6] P. Korshunov and S. Marcel, “Deepfakes: A new threat to face recognition? Assessment and detection,” arXiv.org, 2019.
[7] S. Hussain, P. Neekhara, M. Jere, F. Koushanfar, and J. McAuley, “Adversarial deepfakes: Evaluating vulnerability of deepfake detectors to adversarial examples,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021.
[8] T. T. Nguyen, C. M. Nguyen, D. T. Nguyen, D. T. Nguyen, and S. Nahavandi, “Deep learning for deepfakes creation and detection: A survey,” arXiv.org, 2020.
[9] H. Qi, Q. Guo, F. Juefei-Xu, X. Xie, L. Ma, W. Feng, Y. Liu, and J. Zhao, “DeepRythym: Exposing deepfakes with attentional visual heartbeat rhythms,” in Proceedings of the 28th ACM International Conference on Multimedia, 2020.